
DNA, the genetic code of life, is read over a million times per day to make proteins, the biological molecules that do all the work in cells. If this process goes wrong then it leads to cell destruction or disease states such as cystic fibrosis or cancer. Luckily, the cell has a multitude repair enzymes to make sure that everything is made correctly, but still mistakes can happen. When there are so many safeguards and proofreading steps, how are mismatches still possible?
Keywords: DNA, translation, proteins, wobble pairs.
How Life Processes Work
DNA is the genetic code of life. It stores all the information that color your eyes, that makes your muscles, and that tells your stomach how to digest. Each and every cell in your body has DNA stored in the nucleus, the cell center. DNA, however, does not last forever and it has to be replicated. This is done by a set of enzymes, but most important is DNA polymerase which duplicates both sides of the double helix to make two new DNA strands.

DNA is also the blueprint for making proteins in a process called transcription. A copy of the genetic code is made out of RNA and brought to ribosomes where proteins are made. Molecules called tRNA’s follow the plan and link amino acids, protein building blocks together. They know which block to add next by reading sets of the RNA code called codons. tRNA’s read the codons and bring the corresponding amino acid to assemble the protein.

Both of these processes are crucial to your continued existence. If a mismatch in these processes occur, diseases states can emerge. Of course this takes years worth of mistakes to accumulate into a serious issue. In the case of replication issues, that an error in one replication cycle is assumed to be the correct sequence so it can become amplified with each pass of DNA polymerase. For transcription, the RNA sequence yields the production of many proteins that, if not the correct strand of amino acids, will not be able to perform their correct function.
This seems to be most common in single gene diseases, such as cystic fibrosis, and mitochondrial diseases such as encephalopathy, abnormal brain structure which has also been linked to the Zika virus.
Mistakes are Identifiable
Even though DNA polymerase enzymes are very particular when choosing and pairing nucleotides during DNA synthesis, mistakes occur at a rate of about 1 per every 100,000 nucleotides. This might not seem like much, but a human cell has 6 billion base pairs inside each nucleus which means about 120,000 mistakes every time a cell divides.
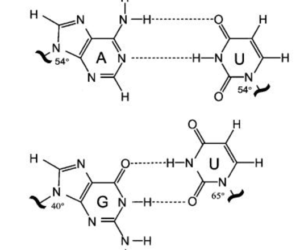
When the wrong nucleotide base is added, there are a few physical indications that flag it to be replaced or fixed. The addition of an incorrect base can lead to the additional twisting in the DNA by either 40 or 65 degrees due to the wrong hydrogen bonds. This strain and torsion are normally identifiable by the repair enzyme so it can add the correct base pair.
Another way mistakes are flagged is if it takes too long for the adjacent base pair to be added: it takes an extra amount of time to add the next nucleotide in sequence if the preceding one is wrong in translation. It’s almost as though the enzyme is uncertain that it’s past actions were correct, at least it would feel skeptical if enzymes could think…
But if evolution has perfected DNA and RNA interactions so to prevent such issues, why can it still happen? What about the interactions are hard to detect?
Mismatched Wobble Pairs
The quick and short answer is that the wrong base pairs can still make hydrogen bonds with each other. However, these bonds are with atoms that don’t normally align, shifting the positions of the bases just slightly. The off-kilter nature of these bonds yield the term wobble base pairs.

Because the base pairs are still making similar H-bonds as they normally do, it can be difficult for repair and proofreading enzymes to find the mistakes. In correct RNA base pairing, G hydrogen bonds with C and A with U so the top two pairs in the figure to the left are proper pairs. However, G can wobble pair with U if the U is shifted slightly upwards, causing the slight angle strain as well.
The most common place that these wobble pairs are seen is within the codon region of tRNA, the area where it reads the RNA to add the correct amino acid. Codons are made of three nucleotide base pairs, where each set of three corresponds to one amino acid. The first two have to be correct for the tRNA to bind, but the third one is less strict in conformation.

Luckily, each amino acid is linked with a few different codons so some mistakes don’t alter the protein made. The RNA code CCU and CCG will both yield the amino acid proline, for example. However, UAU and UAG will mean the tyrosine amino acid or a stop in protein synthesis. This is a drastic difference that results in an incomplete protein all just because of a slight difference in hydrogen bond pairs that was never caught during a proofreading step.
Take Away
Even though mismatches happen all the time, they are normally caught right away and even if they aren’t it takes a very long time for mistakes to have a large impact on human health, so do not worry. But it is so incredible how refined and intricate these systems are, relying so heavily on small hydrogen bonds. Here’s to hoping that our proofreading enzymes stay sharp so we don’t get cancer or diseases!
Sarah is in a graduate program for Chemical Biology at the University of Michigan. She writes for her blog Annotated Science and soon will be published with Michigan Science Writers! You can follow her on Twitter at annotated_sci for more content on science and open access news.
Leave a Reply